That one time Keygen went down for 5 hours (twice)
Wednesday, February 21st 2024
On the morning of February 5th at 6:30am UTC, Keygen Cloud became unavailable for over 5 hours. Then, on the morning of February 6th at 6:30am UTC, Keygen Cloud became unavailable again for over 5 hours. The outage affected all Keygen Cloud services, including the Dashboard, Licensing API, and Distribution API.
Keygen Cloud API clients and consumers would have received 5xx application errors during this time. To all Keygen Cloud users, I am deeply sorry.
What went wrong was a wide range of failures. Some within my control, and some not. But let's start at the beginning, from my perspective.
February 5th
On the morning of February 5th at 10:00am UTC (4:00am CST), I woke up to my phone lighting up over and over again. It was on silent, but I rolled over to check what was going on. What I saw was Keygen's Discord blowing up, text messages from numbers I don't know telling me Keygen is down, and thousands of emails telling me that Keygen is down.
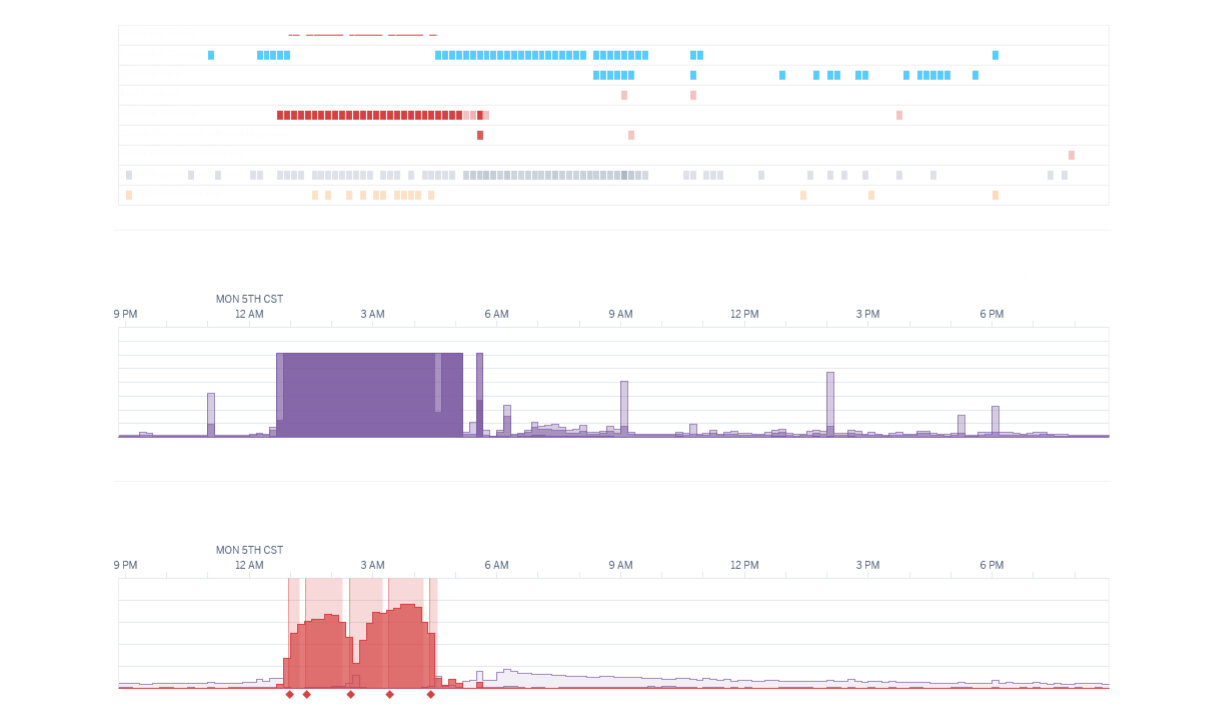
I quickly got out of bed and ran down the stairs to my office. The first thing I did was look at Heroku. Are they down? No. I look at Keygen's application logs to determine what's happening. But the logs are coming through like a firehose and I can barely focus. Then I see Redis errors. A lot of them. I again take a look at Heroku and tab over to my Redis monitoring page. I see that Redis is fine on memory and CPU, but it's timing out.
That doesn't make sense. (It will.)
I take another look at my Heroku dashboard and metrics, and then it hits me: Keygen has been down for 4 hours. This is bad. I try to recompose myself.
I see that my current API volume is an order of magnitude more than what it usually is. Is Keygen experiencing a DDoS attack? Just a week prior, I read about another company, 37Signals, experiencing a DDoS, which was apparently a trend happening to others, per the replies and other tweets (exes? xposts?) at the time.
I wondered if it was a trend that had reached me.
I segment logs on Keygen account and see that one particular account has a considerable increase in volume. This seemed like the right thing to look at.
I looked at the account's traffic in more detail, and it all looked like legitimate traffic. It was just a lot of it. Hundreds and hundreds of requests per second. But if it was a DDoS, it wasn't like any others that I'd experienced. (Besides, a few hundred RPS isn't necessarily hard to handle, and we've handled it before without incident.)
Regardless, at this point, Keygen had been down for 4 and a half hours. I needed some protection, and I needed it fast. I tabbed over to Cloudflare and turned on the little Orange Cloud. (More on why the Orange Cloud was off later.)
I noticed that there were outlier IPs, in terms of API volume, and they were all making requests to the affected account. I began blacklisting these IPs, but although that lessened the firehose, it didn't stop it. The traffic was coming from a variety of IPs, even if some were outliers in terms of volume.
As a last resort, I turned on Cloudflare's "Under Attack" mode, to give Keygen's systems time to recover, and to give me time to investigate.
During the next few minutes, Keygen's systems began to recover. Of course, this was easy, because Cloudflare was effectively blocking all API traffic. You see, when "under attack", Cloudflare begins sending challenge responses to requestors, but the challenge response requires JavaScript in order to solve. Well, Keygen is a JSON API, and API clients — of course — can't solve JavaScript challenges.
On February 5th at 11:30am UTC (5:30am CST), Keygen's systems were recovered for 99% of accounts. Total downtime was over 5 hours. The only account that wasn't recovered was the one being blocked by Cloudflare.
I contacted the account owner to explain the situation, and to ask if they knew of anything occurring on their side that could aid in our investigation.
I wasn't out of the woods yet, though. While I waited for a response from the affected account, I noticed that average response times were still higher than normal. Something was wrong. Nothing looked out of the ordinary, but I still spent the next few hours crawling through logs to see if I could spot a pattern.
In between spelunking logs, I tried my best to catch up on angry emails and Discord chats. I tried not to take it personally, but it was hard not to get emotional. I let Keygen go down for over 5 hours, and I let my customers down.
I was disappointed in myself, I was angry, I was confused, and I was tired. And I still didn't even know what actually went wrong.
At this point, I start to feel like an imposter.
My traffic increased 10x, and I can't handle that? What am I going to do when it spikes 100x? How will I handle that? Will I be able to scale Keygen?
That's when I started to receive messages about response signatures sporadically failing verification. For context, Keygen signs all API responses using an account's Ed25519 public/private keypair. This protects API clients from a variety of attacks, including replay attacks, man-in-the-middle attacks, and spoofing attacks.
The problem was Cloudflare, which I knew right away. If you remember, I turned ON the
Orange Cloud — an in, it was turned OFF before. It was turned off for good reason, too.
You see, Cloudflare's CDN does something that I didn't expect: it modifies the Date
header sent by Keygen's servers. Most of the time, our Date headers agree, but if
Keygen's servers send a response at 14:01:26.993239, then Cloudflare's CDN is going
to set the Date header to something like 14:01:27.000000.
Note the difference in the second portion. By the time Cloudflare "sent" the response,
the Date had changed, because we were at millisecond .993239.
This is a problem, because our response signatures use the Date header to prevent
replay attacks. And if the response's Date header changes out from under us, then
the signature is invalid, and the API client will reject it.
This is a known issue with Cloudflare, and one I brought to their attention in August of 2021. There is no known workaround, because you can't bypass Cloudflare's CDN if the Orange Cloud is on. They essentially marked it as "won't fix" — which is fine — that's their right. But it left Keygen unable to use the Orange Cloud and without a WAF.
For years, it had never been an issue (even if it was unwise), but today, I'm in a bind:
If I enable the Orange Cloud, API clients reject responses roughly 10% of the time.
If I disable the Orange Cloud, Keygen goes down.
I chose to keep the Orange Cloud until I could get a response from the affected account.
For some customers that were able to push out updates, I recommended them to change
their response signature verification methods to use the Keygen-Date header, which,
in hindsight, is what I would have used. But I didn't know Cloudflare's CDN behaved
this way until our response signatures were out in the wild for months.
And sure, we could change behavior for new accounts and help accounts migrate, but I
didn't agree with the behavior by Cloudflare's CDN. It wasn't acting as a good proxy.
The HTTP spec
describes the Date header as the time at which the message originates,
and "the message" originated on our servers, not Cloudflare's:
"When a
Dateheader field is generated, the sender SHOULD generate its field value as the best available approximation of the date and time of message generation. In theory, the date ought to represent the moment just before the payload is generated. In practice, the date can be generated at any time during message origination.""The HTTP-date sent in a
Dateheader SHOULD NOT represent a date and time subsequent to the generation of the message. It SHOULD represent the best available approximation of the date and time of message generation."
So their behavior seems wrong, at least from my point of view.
Anyways, enough about Cloudflare's CDN.
At this point, Keygen's systems had mostly recovered. So I turned off "Under Attack" mode to see where we were at. Immediately, the systems started having trouble again. The traffic was still high. Instead of turning on "Under Attack" mode again, effectively blocking all API traffic, I decided to block the problem account. So I set up a firewall rule in Cloudflare to block any request matching their account ID.
I sent the account owner another email indicating our course of action, again requesting any information they had on their end.
Keygen's average response times were still high, and I'm still spelunking through the logs to determine why that's the case. The API endpoints showing high response rates seem random, like everything is just slower since the incident.
A little while later, I received a response from the account owner. Their response indicated that they had onboarded new institutional customers based in Europe, and that the spike in traffic was likely from that, since it was Monday. This would explain the outlier IPs — they were institutions with thousands of users.
After a few back and forths, we determined that (a) Keygen was not prepared for such a large increase in traffic, and that (b) the customer's retry-logic was flawed.
For most API integrations, when a failed request occurs, the request is retried again with an exponential backoff. What that means is that on failed request, the request is retried in 1ms, then 100ms, then 10000ms, etc. But their integration didn't do that. Instead, they retried more often each time the request fails.
Due to this, what we determined is that their volume increase caused what is called an unintentional DDoS. The increase in traffic caused our systems to fail, which caused their systems to DoS our systems, which caused our systems to stay down.
After more back and forth, we determined that if we were able to let a small amount of traffic through, their systems could recover and stop hammering our systems. Otherwise, their systems will unintentionally DDoS us every morning at 6:00am UTC until they're able to push out an upgrade with a fix for the retry behavior. But the timeline on that was weeks for the upgrade to propagate through their userbase.
Of course, we didn't have weeks. On their side, after a successful license validation, their application wouldn't request another validation for a few days. This would buy us time. So we agreed to use Cloudflare to rate limit their account, to let the firehose trickle in, and eventually fully drain it. Until the few days are up, and then we repeat.
So we did. And it was working. By our calculations, by end of day, the firehose would be drained and the spike wouldn't (theoretically) occur again for a few days. That would give me time to diagnose our scaling issues and implement a rate limiter that didn't depend on Cloudflare's problematic Orange Cloud.
At this point, I was working on 4 hours of sleep. I was exhausted, but I felt like I couldn't leave my post. I skipped lunch that day, spending all my time spelunking logs and responding to emails. Not my favorite day, that's for sure.
After awhile, the firehose was empty. I disabled the Orange Cloud, and the systems were still operational. We didn't go down. According to our estimates, these new institutions won't hammer our API again for 3 days, and an upgrade is being pushed out that should propagate to at least a percentage of end-users over the next 3 days, hopefully limiting the amount of end-users with the flawed retry logic.
Either way, I knew in 3 days, come February 8th, we'd experience a thundering herd at 12:30am UTC. I had to prepare for that. I scaled up infrastructure, beyond anything we'd reasonably need, but I wanted to be overprovisioned to avoid the same cascading failure we had experienced. And I wanted to be able to sleep.
Meanwhile, even though the firehose was empty, Keygen's systems were still performing slower than average. And it was infuriating not knowing why.
I still had lingering questions that demanded answers:
Why could we not scale up to support the additional traffic?
This was 200-400 RPS. I felt like we should've been able to handle that, but for some reason, we couldn't. We've scaled up an additional 200 RPS before for other customer launches without issue. What's different?
Why is the poor performance so intermittent?
What is different about this traffic?
At this point, it's around 3pm, and I wanted to start winding down for the day. I needed some rest, and a shower, but I wanted to make sure this didn't happen again.
I reflected on what went wrong from an alerting standpoint:
- Our pager service, Better Uptime, was not configured to send phone call alerts in the event of an outage due to an oversight in our on-call configuration.
- The on-call engineer's (a.k.a. me) phone was placed on DnD mode (do-not-disturb) at 6:00am UTC (12am CST), right before the incident.
- The email alerts were not seen due to DnD mode being enabled (I was asleep).
- The calls and texts from enterprise customers were not seen due to DnD mode.
- The pager service's text notifications were not whitelisted from DnD mode.
- There were no escalation policies for paging more aggressively.
I put in place a few things to remedy those failures:
- I configured an "Emergency Bypass" for my pager service's phone number. This would allow them to audibly page me even if my phone is on silent or DnD mode.
- I assigned myself as the default "on-call" engineer.
- I set up a more aggressive escalation policy.
On the evening of February 5th at 11:00pm UTC (5pm CST), I signed off. This was one of the worst days of my professional career. I had an outage exceeding 5 hours, and I still have no idea what went wrong. I left my office feeling defeated.
February 6th
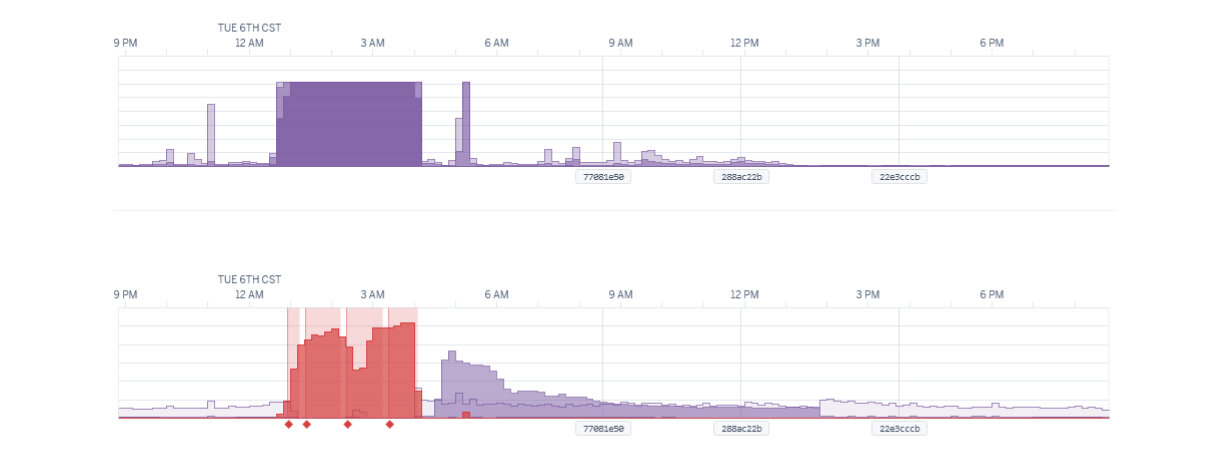
On the morning of February 6th at 6:30am UTC (12:30am CST), I woke up to my phone lighting up over and over again. It was on silent, and I looked at the time and jumped up knowing full well what was going on. Keygen had been down for over 4 hours before I woke up and was made aware, AGAIN. I'm reliving my nightmare.
I thought I just went through all that effort to bypass DnD mode?! Turns out, of course, that the pager service doesn't have a static phone number. Stupid me.
I felt dread.
I had to turn the Orange Cloud back on AGAIN, which caused the signature verification failures AGAIN, and I blocked the account AGAIN. Keygen's systems began to recover, and just like that I am literally reliving the worst day of my career. Even down to the time I woke up. I failed AGAIN, letting Keygen go down for over 5 hours.
But I didn't have time for sulking. I needed a solution FAST.
I spent some time implementing an account rate limiter on the application-side so that I could changeover from Cloudflare's rate limiter to my own, in hopes that I could turn off the Orange Cloud (because it's breaking API clients).
I ran some local tests and deployed the rate limiter. Then I began rate limiting the affected account, and eventually I was able to turn off Cloudflare's Orange Cloud. The firehose was trickling in a controlled manner, and I was able to modify the rate limiter to only rate limit a subset of requests, to allow a full "licensing flow" for end-users, to make sure their workflow is "complete", starting the 3 day timer for each end-user.
At this point, the dreaded Orange Cloud is off, and the new rate limiter is letting the firehose trickle in. I have some breathing room.
What happened?! I thought yesterday's firehose was empty?
I contacted the account owner, trying to gain some insight. They gave me more context, explaining that they are rolling out to many new institutions, and these new institutions will be onboarded throughout the next 2 weeks.
I pondered a couple questions that again demanded answers:
Today's firehose was less volume than yesterday's, but it was still enough to take Keygen down — why can't I handle this traffic?
Something was different about this customer's workload compared to others — what's different about this traffic?
First and foremost, I wanted to know the answer to the latter question — what's different about this customer's traffic? I once again began spelunking the logs. I stared at endless logs, trying to find any pattern at all, but nothing stood out.
Here's what I knew: once the firehose started, Keygen's response times would grow and grow over the course of a few minutes, until it eventually began timing out. If I turned off the rate limiter, the same thing would happen: response times would grow for a few minutes until everything begins timing out.
Where's the bottleneck?!
Before I signed off the previous day, I installed Sentry to help me diagnose performance issues, and to improve error tracking. Before that, Keygen had no APM or error tracker. All performance monitoring at the time was done using custom queries on request logs, and Heroku's slow query logs and monitoring tools, while error reporting was done via rudimentary email reports on stderr via our logging service.
Why didn't Keygen have a proper APM? Well, after racking up a $14k bill over the course of 48 hours with an APM in the past, I cut the APM cord and never revisited it. But I was comfortable with Sentry because they didn't have usage-based pricing.
(They're also open source, so it was a fit for Keygen's self-hosted options.)
But I digress —
Using Sentry, I looked at the typical request flow for some of their end-users. It seemed normal — they'd validate a license key, activate a machine if it wasn't already activated, and then send a heartbeat ping for the machine.
The license key validation requests had an average response time of 30 milliseconds. The machine activation requests, 50 milliseconds.
Then I saw it: the heartbeat ping response times varied from 10 milliseconds to 10 seconds. Yes, 10 seconds. Something was very, very wrong.
How could that endpoint take 10 seconds to respond?
Literally, all it does is queue a background job into the future. That job, when run, checks if the machine is still "alive." If it isn't, and the machine hasn't been deactivated normally, it's considered a "zombie" machine and is automatically deactivated.
(This was a poor design decision that I knew was going to eventually bite me.)
Queueing a background job should take a few milliseconds, not seconds.
I tabbed over to Sidekiq's admin UI (Sidekiq is Keygen's background job processor), and everything looked relatively normal. Again with the normalcy.
Well, except for the schedule queue! It had 1 million scheduled jobs. Typically, the schedule queue would hover around 20 thousand and it would largely clear itself out by end of day. A queue of 1 million is orders of magnitude more.
Why is this queue so full?
I dig into the queue and see that it's full of heartbeat jobs.
I had a hunch. I open up a console and look at the account's policy settings, and I see that their workflow has a heartbeat duration of 1 month.
Most accounts set a heartbeat duration of 10 minutes, so it makes sense that the schedule queue would be larger, because heartbeat jobs are being scheduled out 30 days instead of 10 minutes, and they have a lot of end-users. So jobs keep piling up.
Okay. That answers the question of why the queue is so full, but why is pushing to the queue slow, and why is performance so sporatic? Pushing an item onto a Redis sorted set should be O(log(n)) i.e. fast. Something else must be happening with these jobs.
Then it hits me like a ton of bricks. I'm enforcing job uniqueness per-machine, so that any one machine can't spam the schedule queue and balloon memory consumption. To do this, Keygen is using a popular plugin for Sidekiq called sidekiq-unique-jobs.
What if their uniqueness algorithm isn't performant for large queues?
I started to dig into the source code, and my hunch was right.
When enforcing uniqueness, i.e. for each job push, sidekiq-unique-jobs iterates the entire Redis sorted set (queue), performing a string-find on each item in the set.
local function delete_from_sorted_set(name, digest) local per = 50 local total = redis.call("zcard", name) local index = 0 local result while (index < total) do local items = redis.call("ZRANGE", name, index, index + per -1) for _, item in pairs(items) do if string.find(item, digest) then redis.call("ZREM", name, item) result = item break end end index = index + per end return resultendFor queues where N is small, this is OK. But for queues where N is large, this is unscaleable. To make matters worse, the implementation used Lua to iterate the queue, and since Redis is single-threaded, each iteration was blocking.
This explains the Redis timeouts while having low memory and CPU usage. Redis wasn't overloaded, it was just blocked.
The solution here would be to (a) stop queueing jobs into the future, and (b) make a patch to sidekiq-unique-jobs to improve performance.
The fastest path to victory here was (a), so I chose that. I could do (b) later once my livelihood wasn't at-risk.
Luckily, I had already begun work on moving away from scheduling jobs into the future, because I knew it would bite me. I quickly pushed out a change that would stop queuing jobs into the future, and instead it would use a cron job to cull dead machines, which was already running due to some edge cases in the scheduling system.
Instead of heartbeat jobs being pushed to the schedule queue essentially at random, the heartbeat jobs would now be pushed to the working queue every 2 minutes.
At the time, the schedule queue had over 1 million jobs in it, while the working queue was very small (typically well under 100), since jobs are almost instantly popped from the working queue as Sidekiq churns through them.
My thinking was: once this change was deployed, the heartbeat jobs in the schedule queue would be superfluous; meaning I can begin to manually clear them out.
For a little while, performance would degrade — every 2 minutes — when new jobs were queued via the cron job. But once the schedule queue cleared, the performance issue should go away, because sidekiq-unique-jobs would no longer be iterating 1 million jobs every time Sidekiq pushes a new job onto the queue.
Once the change was deployed, I began to visually see this phenomenon.
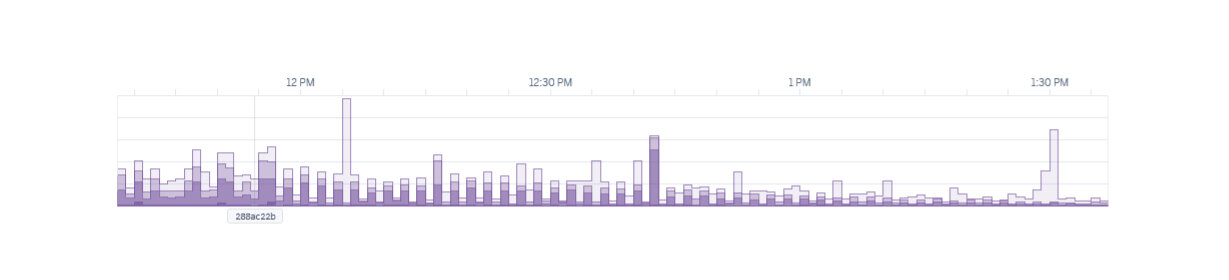
I was never more excited to see a chart show spikes. Every 2 minutes, the cron job would run and response times would spike as the shrinking queues were synchronously iterated checking for uniqueness conflicts.
After the schedule queue had cleared, API response times were faster than ever. I slowly disabled the rate limits on the affected account, and the remainder of the firehose was served successfully.
February 7th
On the morning of February 7th at 6:00am UTC (12:00am CST), I stayed up late and monitored the next traffic spike to ensure that we didn't go down again. We successfully served all traffic without incident. At 8:00am UTC (2:00am CST), I signed off. That night, I slept in the guest room and kept my phone on loud, just in case. But I had a good feeling that the scaling problem was resolved, and it was.
Since the incident, our overall response times have drastically improved. We didn't understand until after the fact how much of an effect this bug had on our performance, even with a nominal schedule queue of 20k. For years, I couldn't figure out why performance was so sporadic.
I always thought it was noisy neighbors on Heroku, but even after moving to P-L dynos, the performance issues still lingered. Now I know that it was me.
I've opened up a PR for sidekiq-unique-jobs
with a proposal on resolving the performance issues, using sorted set
scoring and ZRANGE to limit the search space required. (If you have
better ideas, feel free to chime in.)
As part of the resolution to this incident, I have already implemented or am working towards the following:
- To protect Keygen from DDoS (even unintentional ones), we have employed Fastly's Next-Gen WAF. This means that, in the future, we never have to turn on Cloudflare's Orange Cloud and disrupt existing API clients. We are now protected at all times.
- Replace sidekiq-unique-jobs with Sidekiq Pro and/or Sidekiq Enterprise, which offers better performance characteristics, coming from the creator of Sidekiq. This is a complex change, since Keygen is also self-hosted. It has to be opt-in, since most Keygen CE installations can't afford Sidekiq Enterprise.
- Better alerting and paging. We're exploring our options in terms of pager services, and ways that we can bypass silent and DnD mode for certain types of alerts. If you have any recommendations, please share.
If you made it this far, thank you. If you were affected by this outage, I sincerely apologize. It was a nightmare come true, as I'm sure it was for some of you as well. I understand the importance of business-critical software such as Keygen, and I regret my failings in terms of response time (twice), and any lack of communication.
But in the end, we came out stronger than ever.